Hello. I’ve successfully configured a Rockstor VM under Muvirt (w/DPAA2). This is thanks to all of the great help I received in this thread.
I’ve added 2 scratch disks to the configuration and built out a pool in Rockstor. Reading through the Rockstor guide here, it states: “virtio drives, although more efficient, are currently not supported.”
I’ve configured the disks for the VM as folows:
$ uci show virt.rockstor.disks
virt.rockstor.disks=’/dev/mapper/vmdata-rockstor,serial=ROCKSTOR’ ‘/dev/sdb,serial=STORAGE1’ ‘/dev/sdc,serial=STORAGE2’
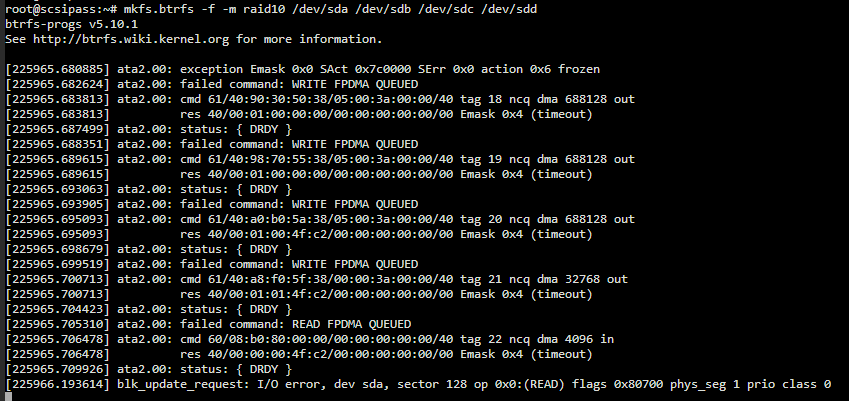
The script /etc/init.d/muvirt appears to add/force the type virtio-blk for the disks. I know this isn’t a forum for Rockstor, but does anybody have recommendations to share on this? Should I be forcing type sata-blk or something similar in the /etc/init.d/muvirt script for example?
I should note that with virtio-blk, I was able to successfully create a pool under Rockstor and write/ready data to the test share. I do note that SMART status is not available however.
Regards,
Gabor