What’s the recommended way to upgrade muvirt if it was installed with baremetal-deploy?
If you used baremetal-deploy, you have a disk install.
You can download the latest “.img.gz and sysupgrade (ext4)” file (muvirt-…-img.gz) from archive.traverse.com.au and upload it to the upgrade section in LuCI or using sysupgrade on the device itself.
Hello @mcbridematt . It’s been a while since I posted. I actually just updated muvirt on my Ten64 where I had two critical VMs - one being Rockstor, and the other being a Fedora VM hosting an influxdb instance. I updated using the tarball: muvirt-23.05.4-r24012-d8dd03c46f-armsr-armv8-generic-ext4-combined.img.gz.
However, neither of my VMs start now, and I think that their respective virtual disks may have been overwritten by the new image. If that’s the case, I probably can’t do much at this stage other than rebuild things. That being said, what would be the correct upgrade procedure to use in the future?
Just an update. It seems that the LVMs are gone now after the upgrade. Again, not sure if I went about the totally wrong way of updating at this stage. The one I’m most concerned about is Rockstor, which I had installed in a OpenSUSE VM for which I built a custom kernel for DPAA2 support. Does the Rockstor appliance in the Appliance Store support DPAA2?
Also, I just tried the “passthrough” script I had on my muvirt install previously to setup the DPAA2 objects. The scripts fails now unfortunately. The script itself follows:
#!/bin/sh
DPMAC="dpmac.6"
DPRC=$(restool -s dprc create dprc.1 --label="child VM dprc" \
--options="DPRC_CFG_OPT_IRQ_CFG_ALLOWED,DPRC_CFG_OPT_SPAWN_ALLOWED,DPRC_CFG_OPT_ALLOC_ALLOWED,DPRC_CFG_OPT_OBJ_CREATE_ALLOWED")
DPNI=$(restool -s dpni create --container="${DPRC}")
restool dprc connect dprc.1 --endpoint1="${DPMAC}" --endpoint2="${DPNI}"
restool dprc assign "${DPRC}" --object="${DPNI}" --plugged=1
DPBP=$(restool -s dpbp create --container="${DPRC}")
restool dprc assign "${DPRC}" --object="${DPBP}" --plugged=1
DPCI=$(restool -s dpci create --container="${DPRC}")
restool dprc assign "${DPRC}" --object="${DPCI}" --plugged=1
for i in $(seq 1 2); do
THIS_DPMCP=$(restool -s dpmcp create --container="${DPRC}")
restool dprc assign "${DPRC}" --object="${THIS_DPMCP}" --plugged=1
done
for i in $(seq 1 2); do
THIS_DPCON=$(restool -s dpcon create --container="${DPRC}" --num-priorities=2)
restool dprc assign "${DPRC}" --object="${THIS_DPCON}" --plugged=1
done
DPIO=$(restool -s dpio create --container="${DPRC}" --num-priorities=2)
restool dprc assign "${DPRC}" --object="${DPIO}" --plugged=1
restool dprc show "${DPRC}"
# Add to be able to connect devices directly to the dpmac.8 and get address from Turris.
/usr/bin/ls-addni dpmac.8
Note that this script is based on the example here. It fails with:
root@muvirt:~# /usr/bin/passthrough
MC error: Unsupported operation (status 0xb)
Invalid --endpoint2 arg: ‘’
Invalid --object arg: ‘’
dprc.4 contains 7 objects:
object label plugged-state
dpbp.5 plugged
dpci.2 plugged
dpmcp.36 plugged
dpmcp.35 plugged
dpio.10 plugged
dpcon.22 plugged
dpcon.21 plugged
MC error: Unsupported operation (status 0xb)
For me this was a bit of a black art to get setup - not sure if you recall all of the issues I hit once upon a time. Is the restool command a newer version in this build which doesn’t work with the previous options?
Did the rest of your system configuration carry over? If it is a really old image (OpenWrt 21.02 based), the location of the configuration backup changed from /boot to / . If that’s the case, you can just move /sysupgrade.tgz from /boot to / and reboot, and the upgrade will complete successfully.
(* You might need to mount /boot manually, e.g via mount /dev/nvme0n1p1 /boot to see it’s contents)
The other possibility is that there might have been a mismatch between the partition sizes in the old and new images.
In the older OpenWrt and muvirt images, I copied across the upgrade script from x86 which didn’t do a good job of preserving things, if the /boot and / partition sizes did not match, it overwrote the partition table from the new image!
The upgrade mechanism now uses a different method which is much, much safer and never changes the partition table on disk.
If you haven’t done anything else on your system since upgrading, you might be able to use “testdisk” or a similar tool to recover any lost partitions.
No, it uses the standard OpenSUSE kernel which doesn’t support the DPAA2 passthrough. You will need to compile your own kernel to support guest passthrough.
Yes, you will need to grab a restool version corresponding to the MC firmware you have (I’m guessing that is 10.20). You can try this one: https://archive.traverse.com.au/pub/traverse/ls1088firmware/openwrt/branches/arm64_2102/623374118/image/packages/restool_LSDK-20.04-2_aarch64_generic.ipk
FWIW The DPAA2 passthrough is broken on newer management complex firmwares (beyond 10.20), though I have been able to keep it running on newer kernels. The kernel patches never got accepted upstream either ![]()
You might be better off migrating to a standard bridge/vhost-net setup, while the overhead on the host side might be higher, I’ve found the throughput on the VM side is much better.
I will look at this in the next hour or so - to see what can be recovered.
I’m a bit surprised by what you said about DPAA2 versus the standard bridge/vhost-net. For some reason I thought I could get better bandwidth using DPAA2.
Is there a way I can check the MC firmware version?
Would you have the list of all of the updates to the kernel sources needed? I’ve not looked at this for ages. But I’m wondering if it’s even worth it give that it never made it upstream.
Ultimately I want to get the best possible I/O performance from my Rockstor VM.
In my experience, it works nicely for VMs with a single Ethernet port passed through (like your Rockstor VM), but not so much for more complicated setups (like ‘routers’ with two or more ports) as there are some architectural limitations that get in the way.
The “achilles heel” of sorts with VFIO on the LS1088 is that while the hardware I/O is virtualized, the interrupts are not.
When an interrupt is generated by the hardware, it has to be proxied via KVM, adding significant latency as the CPU core has to switch in and out of the virtual machine context. (This answer on StackOverflow explains it better than I can!)
A similar issue existed on x86 in the early 2010’s leading to the introduction of features such as APICv. I understand Arm added a similar feature with their 4th generation interrupt controller (GICv4)
I believe this is the reason why certain devices (such as SATA controllers and some WiFi cards) do not work reliably under VFIO.
The other part of the problem is that I think some tuning of the DPAA2 setup is required so the resources (queues/buffers/etc) are properly setup in a guest VM.
restool -m should give you the answer:
$ restool -m
MC firmware version: 10.20.4
I did not change the MC firmware version until the newer 0.9.x system firmware releases, so it is very likely you have 10.20.4 as well.
The 301,302 and 303 patches here are relevant to DPAA2 passthrough:
Sadly, I’ve removed the SATA boot disk from the enclosure and attached it to two different Linux boxes (one arm64, one x86_64) and in both cases I see:
[ 982.205817] scsi 4:0:0:0: Direct-Access PQ: 0 ANSI: 2 CCS
[ 982.214924] sd 4:0:0:0: Attached scsi generic sg1 type 0
[ 982.215183] sd 4:0:0:0: [sdb] Media removed, stopped polling
[ 982.232265] sd 4:0:0:0: [sdb] 0 512-byte logical blocks: (0 B/0 B)
[ 982.238599] sd 4:0:0:0: [sdb] 0-byte physical blocks
[ 982.244111] sd 4:0:0:0: [sdb] Test WP failed, assume Write Enabled
[ 982.250877] sd 4:0:0:0: [sdb] Asking for cache data failed
[ 982.256422] sd 4:0:0:0: [sdb] Assuming drive cache: write through
[ 982.263402] sd 4:0:0:0: [sdb] Attached SCSI disk
And the device isn’t seen by testdisk in both cases. What’s interesting is that when I boot the Ten64 from this disk, it starts muvirt and I see the two old VM configurations, but the respective virtual disks (files) are gone. Those were on an LVM, which has vanished. I moved from a 22.x version to the latest 23.05.
Not sure if any other recovery option could work here? Is there a testdisk binary available for openWRT? I didn’t see any, and hence I removed the SATA disk and attached to two other systems as I mentioned.
Is there a warning in dmesg about a “corrupt” secondary GPT?
You might be able to use GPT fdisk to read the backup/secondary GPT and recover the lost LVM2 partition.
See “Manual recovery procedures” in the GPT fdisk reference
I think command c (load backup partition table from disk (rebuilding main)) is what you need.
You might end up with the LVM2 back but an unbootable muvirt, but that is a lot easier to deal with than a lost LVM2 partition.
None that I can find. I see that Arch Linux has an arm64 package for it, the easiest way might be to download an Arch root and enter it as a chroot.
Matt, from the recovery environment, is there a location I could pull down a gdisk or fdisk utility? I don’t see it listed in the available packages.
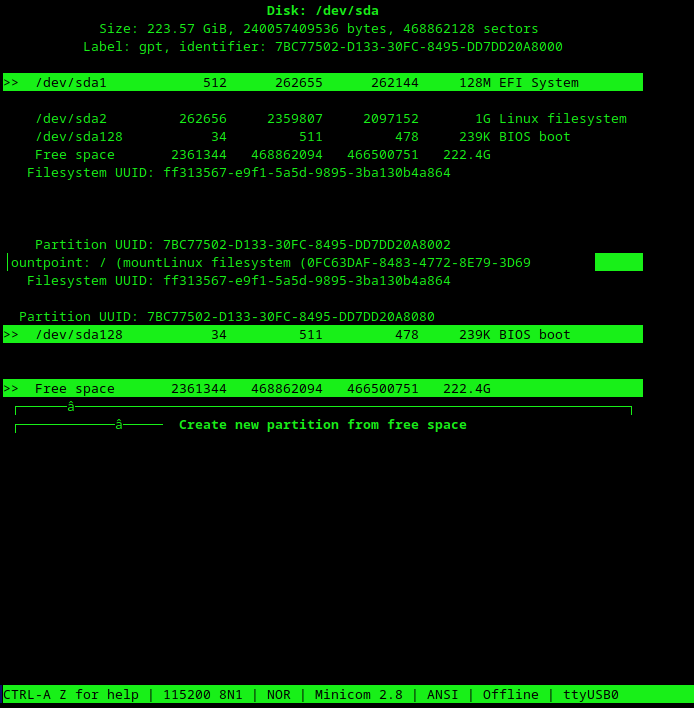
The cfdisk ncurses interface is a bit difficult to use over minicom. But nevertheless, I see the 222 GB of free space, which was likely the LVM. At this stage, no matter what Linux system I connect the disk to, it barfs with with
And I’m unable to use any gdisk etc utility on it. So I think this is pretty much fried at this stage. I need Rockstor working by tomorrow as it was a fileserver used for some important data sharing. So have no choice but to brew some coffee and install everything from scratch at this point sadly.
I’ve had a look in my archives, while I have a few sgdisk (the command line script version) I don’t have any compiled gdisk packages ![]() And you definitely need that gdisk (GPT fdisk) for this type of thing.
And you definitely need that gdisk (GPT fdisk) for this type of thing.
The recovery image has the network block device server (nbd-server), that would be my next method if you can’t read the drive when it’s directly installed in another machine.
@mcbridematt I did bite the bullet and reinstall the main SATA disk with muvirt again. Now I’m hitting issues when trying to create both the Rockstor and an Ubuntu 22.04 release. I wasn’t certain how to configure the VM storage when that prompt came up. That is what sets up the LVM2. Are there logs I can refer to in order to understand why I’m getting the error “download-failed”?
It should all come out in the system log (via logread or via the log viewer in LuCI)
.
If not, running muvirt-provision <vmname> will run the process manually, and that should identify where the issue is.
@mcbridematt Just a quick update here. I ended up doing a complete reinstall of muvirt on bare metal and re-creating the Rockstor and the InfluxDB database instance (on Ubuntu). I’ve setup a second Rockstor instance to try to rebuild the kernel for DPAA2.
FYI The qemu in muvirt does not have the DPAA2 passthrough feature at the moment (that too did not make it fully upstream, so muvirt carried an older copy). I’ll look into getting it back in there.
1 Like
Hello @mcbridematt
Thanks for letting me know. I was about to post that after compiling the kernel in the VM with the requisite patches for DPA2, this is the result:
root@muvirt:~# /etc/init.d/muvirt start rockstor2
Starting VM rockstor2
Disk 0: /dev/mapper/vmdata-rockstor2,serial=236E687F
Network 0: lan
MAC: 52:54:00:be:54:7d
/etc/rc.common: eval: line 306: can't create /sys/bus/fsl-mc/drivers/vfio-fsl-mc/bind: nonexistent directory
The configuration of the VM:
root@muvirt:~# uci show virt.rockstor2
virt.rockstor2=vm
virt.rockstor2.mac='52:54:00:BE:54:7D'
virt.rockstor2.network='lan'
virt.rockstor2.enable='1'
virt.rockstor2.memory='4096'
virt.rockstor2.imageformat='qcow2'
virt.rockstor2.checksum='sha256:2198aad8dae09f16467887584998d5ec1c549bab0dbc247586031f41601c76d4'
virt.rockstor2.imageurl='officialdistro-rockstor|https://rockstor.com/downloads/installer/leap/15.4/aarch64/Rockstor-Leap15.4-ARM64EFI.aarch64-4.5.8-0.qcow2'
virt.rockstor2.numprocs='1'
virt.rockstor2.bios='/lib/muvirt/u-boot.bin'
virt.rockstor2.disks='/dev/mapper/vmdata-rockstor2,serial=236E687F'
virt.rockstor2.provisioned='1'
virt.rockstor2.dpaa2container='dprc.2'
Hello @mcbridematt All the best for 2025!
I’m wondering if there are still plans to add the DPAA2 passthrough feature back into muvirt?Thanks in advance.
If it can be done without holding back other software versions, yes.
The main blocker at the moment is QEMU. The DPAA2 passthrough patches will not apply to recent versions as there were changes to QEMU’s internal APIs. Updating the patch set is theoretically possible, but it would take quite a bit of effort.
What I am planning to do is to add an older, passthrough capable QEMU as a separate package (like qemu-dpaa2) and anyone wanting to use DPAA2 passthrough will need to uninstall the regular QEMU and install that one instead.
@mcbridematt Thanks for letting me know. I’d be willing to use an older QEMU to gain this capability once again. I’ll keep an eye here if the proposal works out.